When I joined Streamr as CMO in 2022, there was no proper commercial infrastructure.
No CRM. No systematic contact database. No repeatable process for finding partners, investors or advisors. Business development was happening through relationships, events and opportunistic conversations.
Those things mattered, but they did not scale.
By the time I became CEO, I needed a system that could keep discovering relevant targets, enrich the data, preserve relationship context and give the team useful next actions without requiring constant manual administration.
That became the first version of an agentic lead generation system.
The business problem
The challenge was not "find more leads" in the abstract.
Streamr needed several different pipelines at once: DePIN ecosystem partners, infrastructure companies, strategic investors, government contacts and advisors who could help with specific commercial problems.
Each group needed different context, different evidence and different messaging. A generic lead list would have created more work rather than less.
The system had to do four things well.
- Find relevant companies and people from defined target categories.
- Enrich them with contact details, LinkedIn profiles and recent signals.
- Preserve relationship context so outreach did not feel cold or random.
- Prepare recommendations humans could review quickly.
That is a systems problem, not a spreadsheet problem.
The stack
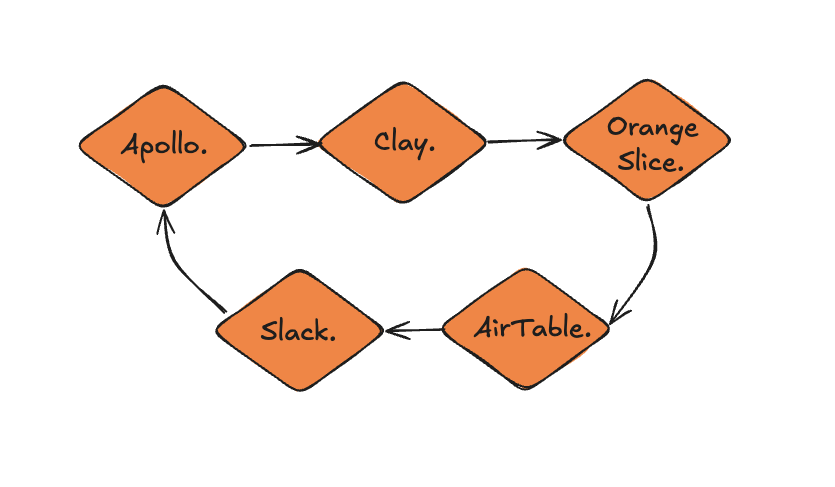
The working stack was deliberately practical.
- Claude acted as the orchestration layer: the place where the task could be described in plain English.
- Hermes ran the recurring work on a VPS, so discovery and enrichment were not tied to my laptop.
- Apollo handled initial people and company search.
- Orange Slice turned plain English research instructions into enrichment work across each row.
- Clay added waterfall enrichment where verified contact data mattered.
- Google Sheets remained the shared operating surface for the team.
- GitHub held the playbooks, ICP definitions, prompts and audit trail.
The lesson is that the tools are less important than the separation of roles. Claude is the interface. Hermes is the executor. Sheets are the operating surface. GitHub is the memory and audit layer.
The architecture
The system followed a simple pattern: inputs, core context and outputs.
Inputs included public company data, funding announcements, ecosystem research, event lists, meeting notes, existing contact sheets and signals from the team's daily work.
The core context had two parts.
First, the knowledge graph: companies, contacts, relationships, previous conversations, warm paths, current status and next action.
Second, the brand foundation: Streamr's positioning, target sectors, partnership value propositions, messaging rules and disqualifiers.
The outputs were practical: enriched rows in Google Sheets, suggested LinkedIn messages, email drafts, weekly summaries and short recommendations on who was worth attention.
The aim was controlled research and preparation, so humans could make better decisions faster.
Why GitHub mattered
The most important design choice was using markdown files as the system's configuration layer.
The ICP definition, target sectors, search rules, disqualification criteria, Slack summaries, message templates and operating notes all lived in a private GitHub repo.
That gave the system three things a serious client deployment needs.
Version control. If the ICP changes, the change is visible. If outreach quality drops, you can inspect what changed.
Auditability. The team can read the exact instructions the agent is using. There is no black box hidden inside a prompt chain.
Handover. The client or team owns the operating system. They can edit the playbook without asking a developer to rewrite the workflow.
Markdown is useful because operators without technical backgrounds can read it, edit it and understand what the system is doing.
The rollout pattern
I would not start with fully autonomous outreach.
The sensible rollout has three phases.
Phase 1: Discovery and enrichment. The agent finds companies and people, enriches the data, and explains why each target belongs on the list. Humans review everything.
Phase 2: Assisted outreach. The system drafts messages using the knowledge graph and brand foundation. A human approves before anything is sent.
Phase 3: Pipeline learning. The system tracks replies, meetings, source quality and message performance. It then updates the playbook around what actually creates conversations.
The last point matters. Lead generation systems should not be judged by the number of rows created. They should be judged by replies, meetings, referrals and pipeline movement.
What changed when it moved to a VPS
The earliest version ran on a Mac Mini in my home office in Lisbon.
It worked, but it was still a prototype. Machines sleep. Power cuts happen. Local settings change. A system that stops when the wrong machine restarts is not production infrastructure.
Moving Hermes to a VPS changed the operating model. The agent could run continuously, keep state, post updates and execute scheduled work without relying on my local machine.
That is the difference between a useful demo and a system ready for a client.
What I learned
The first useful version should be narrow. Pick one ICP, one output surface and one review cadence. Expand only when the first loop is trusted.
Human approval belongs before outreach. Let the system do research and drafting aggressively, but keep a gate before anything reaches a prospect.
The knowledge graph is the asset. Contact data is a commodity. Relationship context, disqualification logic and source evidence are where the system becomes valuable.
The playbook has to be readable. If the operator cannot understand the rules, the system will drift away from the business.
Want this built for your business?
This is what I build as a fractional CMO: working GTM infrastructure that runs on your data, inside your team's operating rhythm.
If you want a BD pipeline, investor outreach system or agentic GTM workflow built around your data and your team, book a discovery call and we can scope the first useful version.
The first version can be built in a week. The value comes when it keeps learning from real pipeline outcomes.
Want this built for your business?
Practical marketing infrastructure, running on your data, in your voice, with approval gates where they matter.
Book a discovery call